達觀數據 如何用人工智能技術重塑企業級搜索與數據處理服務
在當今數據爆炸的時代,企業每天產生和處理的海量信息構成了寶貴的數字資產。如何高效、精準地從這些非結構化或半結構化的數據中提取價值,成為眾多組織面臨的共性挑戰。傳統的企業搜索和數據服務往往依賴關鍵詞匹配和簡單規則,難以應對語義理解、關聯分析和智能決策等復雜需求。達觀數據,作為國內領先的文本智能處理與人工智能技術提供商,正通過一系列前沿AI技術,深刻重塑企業級搜索與數據處理服務,幫助企業將數據潛能轉化為核心競爭力。
一、企業級搜索服務的痛點與AI賦能
傳統企業搜索(如文檔管理系統、內部知識庫搜索)通常存在“搜不準、搜不全、搜不快”的問題。員工可能無法用精準的關鍵詞描述需求,或者搜索結果排序不合理,遺漏了關鍵但表述不同的相關信息。達觀數據利用自然語言處理(NLP)、深度學習和大模型技術,為企業搜索注入“智能”:
- 深度語義理解與向量化檢索:超越關鍵詞匹配,通過BERT、ERNIE等預訓練模型理解查詢語句和文檔內容的真實語義。將文本轉化為高維向量,在向量空間中進行相似度計算,使得“財務報表分析”的查詢也能精準匹配到標題為“公司Q3營利狀況探討”的文檔。
- 智能問答與對話式搜索:結合知識圖譜和閱讀理解技術,系統能夠直接回答諸如“去年華東區的銷售額是多少?”等自然語言問題,無需用戶翻閱長篇報告,實現“即問即答”的交互體驗。
- 個性化排序與推薦:根據用戶的角色、歷史搜索行為、部門信息等上下文,對搜索結果進行個性化重排序,確保最相關、最有價值的信息優先呈現,提升知識發現效率。
- 跨模態統一搜索:不僅限于文本,還能對圖片中的文字、表格數據、甚至音頻/視頻中的語音內容進行一體化索引和檢索,真正實現企業全域知識的互聯互通。
二、數據處理服務的智能化升級
企業原始數據往往雜亂無章,格式不一。達觀數據提供的智能數據處理服務,將AI貫穿于數據“采、標、管、用”的全生命周期:
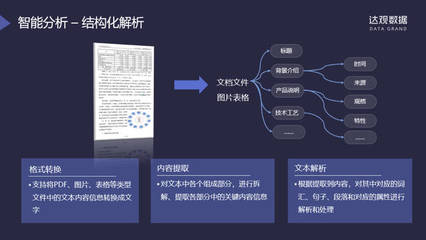
- 智能文檔解析與信息抽取:利用OCR(光學字符識別)和文檔結構理解技術,自動解析各類版式復雜的PDF、掃描件、合同、票據等,準確抽取關鍵字段(如公司名稱、金額、日期、條款等),將非結構化數據轉化為結構化數據,為后續分析奠定基礎。
- 自動化數據標注與質檢:面對機器學習所需的海量標注數據,通過主動學習、預標注模型等技術,大幅減少人工標注工作量,并智能識別數據中的矛盾與錯誤,提升數據集的質與量。
- 知識圖譜構建與動態更新:從多源異構數據中自動抽取實體(如產品、客戶、技術術語)和關系,構建企業專屬的知識圖譜。該圖譜不僅能可視化展示復雜關聯,更能作為底層“大腦”,賦能搜索、推薦、風險洞察等上層應用。
- 流程自動化與智能決策:將上述能力封裝為RPA(機器人流程自動化)的“AI技能”,自動完成合同審核、報告生成、輿情監控、客戶信息錄入等重復性高、規則明確的業務流程,并基于數據分析提供輔助決策建議。
三、重塑價值:從效率工具到智慧引擎
達觀數據通過AI技術重塑企業搜索與數據處理,其核心價值已超越簡單的效率提升工具,演進為驅動業務創新的智慧引擎:
- 提升運營效率:員工查找信息的時間從小時級降至分鐘甚至秒級,數據準備和處理工作實現自動化,釋放人力專注于高價值任務。
- 強化風險管控:在金融、法律等領域,智能搜索和合同分析能快速識別潛在風險條款和違規點,加強合規風控能力。
- 激發業務創新:通過深度數據分析與知識關聯,發現市場新趨勢、客戶新需求、研發新方向,為產品創新和戰略規劃提供數據驅動的洞察。
- 優化客戶體驗:在客戶服務場景,智能搜索幫助客服快速定位解決方案,知識圖譜助力精準推薦,提升服務滿意度與轉化率。
****
達觀數據以前沿的人工智能技術為錨點,通過深度融合自然語言處理、知識圖譜、機器學習等能力,正系統性地解構并重建企業級搜索與數據處理服務。這不僅是一場技術變革,更是企業知識管理和數據利用范式的升級。隨著大模型技術的不斷演進和落地,企業搜索將更趨“對話化”和“創造化”,數據處理將更加“自動化”和“智能化”。達觀數據將繼續深耕于此,助力更多企業駕馭數據洪流,在數字化浪潮中構建堅實的智能基石,邁向決策更智能、運營更高效、創新更敏捷的未來。
如若轉載,請注明出處:http://www.929qp6.com/product/59.html
更新時間:2026-05-14 23:10:06